 0 comments have been left for this article.
0 comments have been left for this article. BP Comment Quick Links

|

|
January 10, 2000 Field General or Backstop?Evaluating the catcher's influence on pitcher performanceEd. note: the following article appeared in Baseball Prospectus 1999. Table of Contents
One of the great remaining unknowns in sabermetrics is the true defensive impact of the catcher. What few commonly available stats we do have to deal with peripheral defensive responsibilities like passed balls and throwing out basestealers. Yet most knowledgeable observers believe that the aspect of the catcher's job that has the most impact is his game-calling, that is, his ability to work with pitchers and help them throw more effectively. The cumulative effect of game-calling is potentially huge. For example, a catcher who catches 130 games a year, and who may reduce the ERA's of his pitchers by just a quarter of a run (0.25) is worth 32.5 runs defensively -- a figure that ranks up there with the top shortstops and outfielders in the league. Yet there have been no satisfyingly thorough attempts to quantify this presumably crucial aspect of run prevention. Currently, the most common way to evaluate game calling in the majors right now is expert evaluation -- in other words, managers' and coaches' opinions and assessments. Ultimately, this approach is contrary to the spirit of sabermetric investigation, which is to find objective (not subjective) knowledge about baseball. What we'd like to discover is a sensible, objective measure that can be used to compare to expert evaluation. The most comprehensive previously published sabermetric study on the topic is Craig Wright's "Catcher's ERA" (or CERA) in his fine book The Diamond Appraised. In it, he develops a process where catchers on the same team can be compared by how well a common set of pitchers perform with each catcher. Wright uses a technique called "matched innings" to control for the differences in how often a catcher worked with each pitcher. The results were labeled Catcher's ERA, and can be used to draw intrateam comparisons among catchers. STATS has gone on to publish CERA in their Major League Handbook, though it appears that they have not used the matched innings to normalize for opportunities; rather, their CERA is a raw report of the team's ERA when that catcher is behind the plate. This makes it less useful for the kind of comparisons Wright investigated. Unfortunately, CERA, even as envisioned by Wright, has several limitations. The first is a problem of sample size. In small numbers of innings (particularly with backup catchers), wide fluctuations are expected. Wright himself does admit this. However, there's little attempt to quantify the amount of natural variation that would be present even if no true game-calling ability was present. Therefore it's impossible to tell how much of the variation should be attributed to simple chance, and how much of it lies with a catcher's actual ability. The other problem is that Wright doesn't systematically check whether game-calling ability correlates from year to year (that is whether good/bad CERA tends to stick around from year to year, as opposed to being random). A true innate ability should manifest itself as good (or bad) players tending to stay good or bad from year to year. That's not to say that you won't see some players flip-flop, but overall, the tendency should be that good catchers should be expected to continue being good the next season, and so on. Wright does use some anecdotal examples to show that Rick Demspey, Mike Macfarlane, and Doug Gwodsz were good defensive catchers, Geno Petralli and Jamie Quirk were poor defensive cathers, and so on. However, without a comprehensive analysis (which was not provided in The Diamond Appraised) it's impossible to tell whether these examples are selected because they serve to make CERA look good, or whether they are truly representative of a larger phenomenon. For the purposes of the following study, I was most interested in isolating a catcher's game-calling ability, separate from other parts of his defensive responsibilities. That is, determining whether a catcher influences the rates of hits, walks, and extra bases a pitcher surrenders to the opposition. This is more focused but more limited than CERA, which incorporates all factors that contribute to run scoring (since it directly measures runs). On the other hand, CERA suffers from the same discrepancies in separating earned runs from unearned runs as basic ERA does. In addition, I'm not trying to measure his ability to control the running game, or throw out basestealers. Nor am I trying to quantify his ability to block the plate and prevent passed balls and wild pitches. By looking solely at the outcomes of batter plate appearances, we can see how well the catcher affected the batting performance of his opponents relative to the other catchers working with the same pitcher. Once we've isolated game-calling, there are two main questions that we must answer before deciding whether we've discovered a measurable ability:
If neither of these conditions exist, then it's likely that any differences in CERA or game-calling are the result of random chance, and are not indicative of an actual skill possessed by the catcher. For this study, I used data from the play-by-play database available from Retrosheet (for 1981-83), and licensed from the Baseball Workshop (now part of Total Sports) for the years 1984-97. This in-depth data includes the complete defensive roster on the field for every plate appearance in every game for the entire season, making it very easy to create aggregate splits for each battery. With 17 years of data collected, concerns about sample size or single-season flukes can be mitigated. For each catcher, I looked at all pitchers with whom he caught at least 100 plate appearances, and generated totals for the pitcher both with and without the catcher. This gave me a sample set of 6347 battery-seasons spanning 17 years to work with, and included a broad and robust base of different kinds of pitchers and catchers. For example: 1997 w/ Catcher Santiago W/o Catcher Santiago Pitcher PA AB B1 B2 B3 HR BBOuts EstPA PA AB B1 B2 B3 HR BB OutsEstPA Hentgen 627 577 98 25 6 13 44 435 621 449 418 75 17 1 18 27 307 445 "EstPA" refers to the number of plate appearances as estimated solely from at-bats, hits, and bases on balls. It does not include hit-by-pitches, sacrifices, catcher's interference, and so on. The significance of this figure will become relevant later in the analysis. After this section, I use PA and EstPA interchangeably to mean the total of hits, outs, and walks (excluding the minor events). To put that in more familiar statistical terms, Pat Hentgen+Benito Santiago gave up an AVG/OBP/SLG of .246/.300/.378 over 621 batters faced. Hentgen with all other Blue Jay catchers combined to allow .266/.310/.440 over 445 batters. In this case Charlie O'Brien caught all the games with Hentgen that Santiago didn't, but generally speaking the "without" column includes totals from more than one catcher. Is the difference between the 678 OPS (On-base Plus Slugging) and the 750 OPS with O'Brien enough to conclude that Santiago was the better game-caller for Hentgen? Or is it within the range of what you'd expect from chance when splitting Hentgen's 1066 total batters faced in these proportions? The details of the calculation are explained in the appendix, but I'll state it briefly here. For each set of data, I computed the average run value of each plate appearance using Thorn & Palmer’s Linear Weights system. This yields a rate value I call Pitching Runs per Plate Appearances (PR/PA). The difference between the PR/PA in each subset of PAs yields a number called Run Prevention Rate or RPR, which represents how many fewer runs the pitcher yielded per batter faced with the catcher in question. Lower numbers are better, as with ERA. Then, I converted RPR and the number of plate appearances into a statistical Z-value. A Z-value represents how likely such a difference would be over a sample size of the number of PA's if the difference were due strictly to chance. The value represents how many standard deviations away from the expected mean (of zero difference) that data point represents. The importance of the Z-value is that it inherently takes into account the effect of small sample size. Like RPR, I designed game-calling Z-scores to follow the same rule as ERA or CERA. Good performance gets lower numbers. In particular, a negative Z-score indicates that the catcher did better than his counterparts with that pitcher. Conversely, a positive Z-score means that a catcher did worse handling a pitcher than the other catchers on the team. Let’s take a look at some of the best and worst performances:
Top 5 catcher splits in each season, 1995-97
Pitcher w/ Catcher Pitcher w/o Catcher
YEAR Pitcher Catcher PA AVG OBP SLG PR/PA PA AVG OBP SLG PR/PA RPR Z-score
1997 DeJean,Mike Manwaring,Kirt 128 .175 .227 .275 -0.067 160 .368 .431 .535 0.093 -0.160 -3.38
1997 Mercedes,Jose Levis,Jesse 165 .182 .212 .296 -0.069 476 .273 .345 .469 0.039 -0.107 -2.77
1997 Smiley,John Oliver,Joe 346 .266 .292 .404 -0.003 313 .335 .396 .570 0.089 -0.092 -2.67
1997 Hill,Ken Kreuter,Chad 146 .176 .233 .316 -0.052 674 .289 .378 .440 0.046 -0.097 -2.59
1997 Watson,Allen Kreuter,Chad 604 .253 .316 .427 0.015 257 .340 .397 .604 0.099 -0.083 -2.50
1996 Lima,Jose Ausmus,Brad 157 .231 .280 .320 -0.031 159 .361 .409 .707 0.133 -0.165 -3.24
1996 Lira,Felipe Ausmus,Brad 423 .222 .288 .341 -0.021 400 .319 .370 .541 0.069 -0.090 -3.00
1996 Tewksbury,Bob Johnson,Brian 272 .214 .243 .305 -0.053 585 .304 .344 .447 0.031 -0.084 -2.84
1996 Thompson,Mark Reed,Jeff 392 .250 .319 .404 0.010 345 .326 .400 .557 0.086 -0.076 -2.36
1996 Keagle,Greg Ausmus,Brad 133 .218 .301 .437 0.012 284 .339 .465 .561 0.114 -0.101 -2.20
1995 Charlton,Norm Wilson,Dan 151 .130 .205 .188 -0.098 123 .267 .374 .362 0.024 -0.122 -2.85
1995 Fernandez,Sid Daulton,Darren 174 .170 .241 .296 -0.053 222 .286 .360 .578 0.076 -0.129 -2.83
1995 Fernandez,AlexLaValliere,Mike 322 .207 .252 .316 -0.045 526 .286 .350 .438 0.032 -0.077 -2.69
1995 Cone,David Knorr,Randy 130 .149 .208 .215 -0.091 813 .241 .315 .396 0.007 -0.098 -2.55
1995 Pettitte,Andy Leyritz,Jim 349 .246 .281 .357 -0.021 386 .298 .383 .463 0.054 -0.075 -2.50
Worst 5 catcher splits in each season, 1995-97
Pitcher w/ Catcher Pitcher w/o Catcher
YEAR Pitcher Catcher PA AVG OBP SLG PR/PA PA AVG OBP SLG PR/PA RPR Z-score
1997 Burba,Dave Taubensee,Eddie 193 .296 .383 .586 0.087 495 .240 .315 .370 -0.001 0.088 2.44
1997 Bergman,Sean Flaherty,John 295 .357 .414 .576 0.097 142 .231 .296 .346 -0.016 0.114 2.56
1997 Burkett,John Rodriguez,Ivan 714 .326 .350 .465 0.039 99 .168 .202 .253 -0.085 0.124 2.77
1997 Mercedes,Jose Matheny,Mike 420 .284 .357 .488 0.050 221 .185 .222 .303 -0.062 0.111 3.13
1997 DeJean,Mike Reed,Jeff 160 .368 .431 .535 0.093 128 .175 .227 .275 -0.067 0.160 3.38
1996 Paniagua,Jose Fletcher,Darrin 107 .351 .430 .606 0.112 111 .218 .288 .287 -0.035 0.148 2.61
1996 Valdes,Ismael Prince,Tom 111 .333 .369 .590 0.084 817 .239 .284 .343 -0.023 0.107 2.66
1996 Peters,Chris Kendall,Jason 123 .389 .463 .611 0.127 153 .210 .261 .392 -0.018 0.145 2.74
1996 Hamilton,Joey Flaherty,John 208 .319 .404 .500 0.072 680 .238 .301 .340 -0.016 0.088 2.80
1996 Grimsley,JasonSlaught,Don 152 .381 .487 .603 0.134 446 .256 .336 .389 0.014 0.120 3.08
1995 Cone,David Parrish,Lance 335 .282 .337 .460 0.033 608 .198 .280 .321 -0.029 0.062 2.24
1995 Bielecki,Mike Fabregas,Jorge 185 .313 .384 .578 0.086 139 .220 .288 .315 -0.028 0.114 2.29
1995 Nitkowski,C.J.Flaherty,John 138 .390 .457 .683 0.144 189 .272 .349 .426 0.029 0.115 2.31
1995 Pettitte,Andy Stanley,Mike 386 .298 .383 .463 0.054 349 .246 .281 .357 -0.021 0.075 2.50
1995 Anderson,BrianMyers,Greg 151 .345 .397 .813 0.158 269 .247 .297 .367 -0.011 0.169 3.54
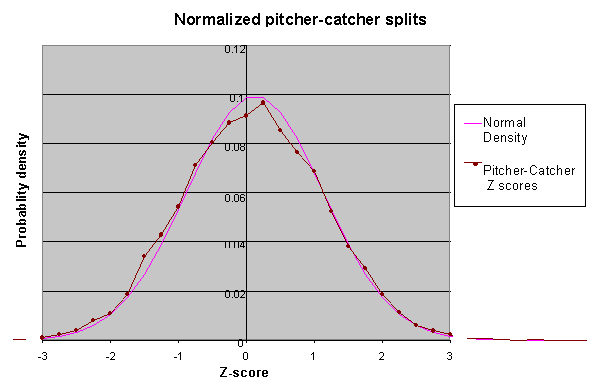
A few things jump out at you: On teams where two catchers work the bulk of the games, the rating of one moves in the opposite direction as the other. So while Kirt Manwaring shined when working with Mike DeJean, turning in a +3.38 Z score, Jeff Reed (who was the only other catcher to work with DeJean in 1997) came in at -3.38. Several other examples can be found on the list above. Also note that Chad Kreuter made the top 5 twice in ’97, and Brad Ausmus made the top 5 three times in 1996. Quite impressive, and if there is a game-calling ability, we have a hint that these two might be the cream of the crop. But we’re getting ahead of ourselves. The next step was to evaluate the data against the null hypothesis that all observed differences between catchers are due to chance, and not to game-calling skills. This will address the first of the two questions posed earlier, and help us determine whether game-calling exists as a measurable ability. In many statistical analyses, data points that are not more than two standard deviations away from the mean are considered to be consistent with the null hypothesis. In other words, Z-values less than two indicate that the difference isn't different from what you'd expect from random variation and no game-calling ability. However, even under the 2 standard deviation rule, you still expect that about 5% of the observations would exceed +-2 std devs. So, what we are really interested in is comparing the shape of the results to the normal distribution. If the shapes match well, then the data is consistent with the no-game-calling-skill hypothesis. So let's look at the distribution of Z-scores from all 6000+ data points:
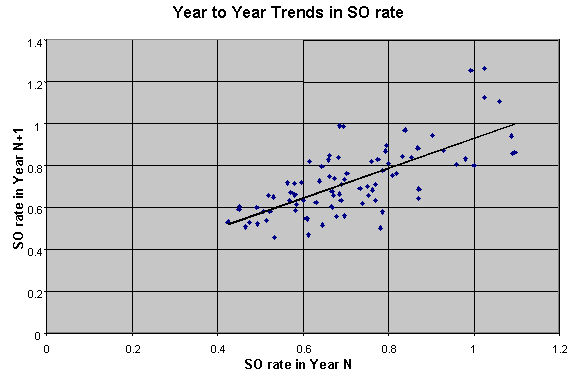
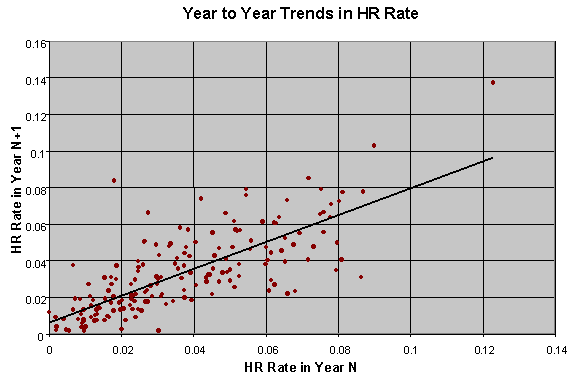
As you can see, the shape of the curve is pretty close to the classic bell curve of the normal distribution. A tiny bit wider and shorter, but otherwise a very good fit. The normal curve is what we’d expect if there were no game-calling ability, and if all differences in splits were due to chance alone. This is pretty good evidence that the distribution of game-calling splits is consistent with the no-game-calling-skill hypothesis. Now this in and of itself doesn't prove that game-calling doesn't exist. For one thing, it’s possible that game-calling ability is normally distributed among major league catchers. However, one thing that a true ability would show is a tendency to persist from one season to the next. For example, we believe that a batter's ability to hit HR's is a true ability, and therefore Mark McGwire is a better bet to hit 40 HR next year than Darren Lewis. Randy Johnson should strike out more batters than Bob Tewksbury. We should be able to look at game-calling ability and see the same tendency--namely, that good game-callers stay good over time, and vice versa. This is the second question posed back at the beginning of our analysis. Do the Hot Stay Hot while the Cold Stay Cold? One way to measure the tendency is to look at the correlation between one year's rate of production and the following year's. Correlation is a comparison between two sets of numbers, in our case game-calling Z-scores in year 1, and year 2. Correlation values range from -1 to +1. A positive correlation means that a high value in one year tends to be followed by a similarly high value the next year. A negative value means that a high value in one year tends to be followed by a low value the following year. Values near zero indicate that there's no relationship between the value in one year and the value the following year. We expect that at true ability should have a significant positive correlation. Indeed, when we look at the correlation in year to year HR rate for players with more than 300 AB between 1996 and 1997, the correlation is +0.76. For pitchers with at least 100 IP, the correlation in year to year strikeout rate is +0.71. However, when we look at the year to year correlation for catchers working with the same pitchers, the correlation is only +0.02. Essentially zero, for all practical intents. How well a catcher worked with a pitcher this year tells you nothing about how they'll work together next year, relative to the other catchers on the club. Nothing. Let alone changes in pitching staff -- a catcher don't even maintain a relative level of performance with the same pitchers. A couple of charts may help illustrate the point of the preceding paragraphs more clearly. A geometric interpretation of correlation is the degree to which you can fit a straight line through the data points, if you plot them on a graph with X values coming from the first series, and the Y values coming from the other series.
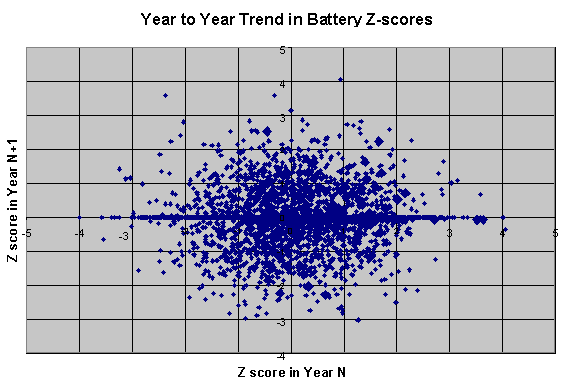
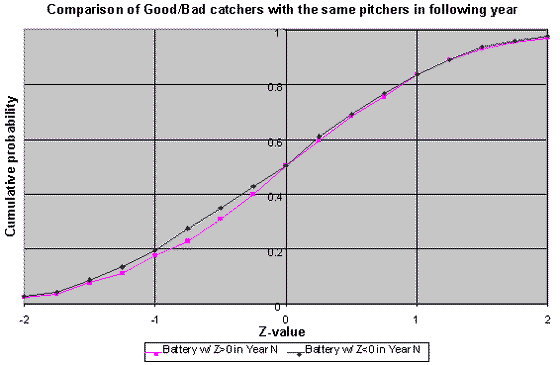
Both of the charts above, which represent year-to-year trends in HR rate (for hitters) and SO rate (for pitchers) show a mostly linear trend. There's a lot of fluctuation around the line, but the general trend for low values in year N are matched with low values in year N+1, and vice versa. Not so with Z-scores:
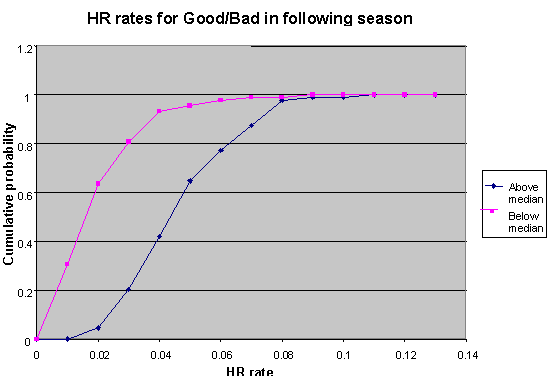
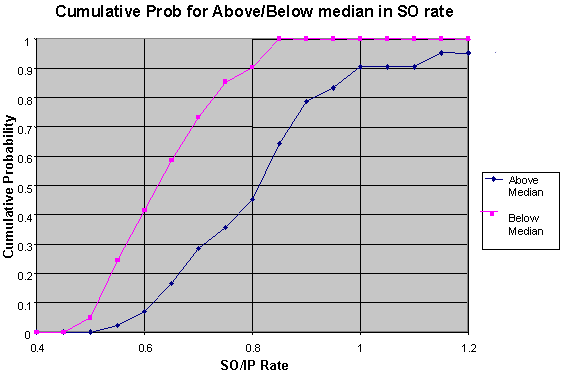
Contrast the shape of this chart with those for HR and SO, and notice how there's no implicit line that can be drawn through the Z-score graph. The dispersal of points is pretty much uniform in every direction, meaning that there's no tendency for good performances in one year to be followed by good performances in the next. Now maybe the problem is that we're looking at all battery combinations. Surely, the batteries who were unusually good or bad together show some tendency to continue, right? Well, let’s find out. We can separate the good from the bad using the Z score. As a first simple pass, let's use better or worse than average. I set up two groups: those with Z<0 (the good) and those with Z>=0 (the bad). Within each group, I looked only at pitcher-catcher pairs that appeared on the list in consecutive seasons. There were 1832 such pairs. The median Z score in the following season for the good group was -0.015 (936 data points with median score in year 1 of +0.73), while the median score for the bad group was -0.003 (896 data points, with median score in year 1 of -0.70). There's little to no evidence we can even differentiate game-calling into good and bad halves, let alone a finer granulation. Well, maybe then we have to give up on separating the mediocre from the slightly above average, but the standouts (in both directions) should surely continue to shine or bumble, right? I repeated the same process, comparing battery combos that were at least one standard deviation away from 0 in one year (that is, either Z>1 or Z<-1), and looked at their performance in the subsequent year. There were 637 battery combinations that met criteria. The 313 members of the >1 group (especially bad combos) had a median Z score of 1.41 in the first year, then returned to average the next season with a median Z score of 0.028 in year 2, and a negligible correlation of +0.04. The 324 members of the <-1 group (especially good combos) had a median Z score of -1.421 in the first season, then also returned to almost exactly average with a Z score of -0.099 and a sign correlation of -0.10 in the followup season. Both groups, despite being selected for usually good or poor performances looked virtually indistinguishable just a year later. We are still an order of magnitude away from even approaching the kind of demonstration of skill we see with other ordinary attributes like power and strikeouts. If home run power was as unreliable as game-calling is from year to year, you'd place even money on Jose Offerman topping Ken Griffey Jr. in the HR race next year. Now this is an important result, and it’s worth exploring why in a little more depth. Go back to the example of home runs for hitters, and strikeouts for pitchers. In each case, we have an intuitive understanding that the ability to do these things is a real skill, something physical or mental about the player that makes him more (or less) likely to hit a HR or strike out an opposing batter than the average player. Indeed, the entire purpose of player evaluation is to look at the past for information about what the future holds. This holds true for major league teams and Rotisserie leagues. Thus, it’s reasonable to ask how this game-calling result might look if there was a strong, demonstrable effect. One way to do this is to construct similar charts for the more familiar HR rate and SO rate. I compared all batters with 300 or more at bats in 1996, and charted their home run rates in 1996. I split the groups into two equal halves--those with HR rates above the median, and those below the median. Then, I followed each group into 1997, and compared their HR rates again. The chart of their results look like the following;
Each point represents the percentage of players in the group (the Y value) who’s HR rate was below the number on the X-value. For example, about 80% of the players who’s HR rate was below the median in 1996 had a HR/AB rate in 1997 below 0.03. On the other hand, only 20% of those who were above the median HR rate in ’96 had a ’97 HR rate below 0.03. The vertical gap between the two line represents the actual differences in ability between the two groups. Now let’s look at SO rate:
Here, we see the same thing. For those who were below the median in ’96, 90% of them turned in a ’97 strikeout rate below 0.8 SO/IP, whereas only 45% of those who turned in high strikeout rates in ’96 were under 0.8 the following season. So to recap, if the above/below line have a large gap between them, then the attribute you are measuring tends to be preserved from year to year, which is characteristic of a real ability or skill. If the lines are close together, previous performance is not related to current or future performance, and thus there is less evidence that a real skill is at work. Now, let’s look at catcher’s game-calling ability:
In this case, the Z-score is the equivalent of HR rate, and Z>0 and Z<0 define our below/above median measurements. As you can see the graphs are very close together, indicating that last year’s performance, doesn’t contribute information about this year’s performance. Our suspicions are rising that we’re not seeing a skill in action. Of course, one catcher and one pitcher don’t work together very much, and the small number of plate appearances they work together creates a lot of statistical variance. Is it possible that looking at catchers’ performance in the aggregate (across several pitchers) would overcome the problem? This is what Wright attempted to do with CERA, using "matched innings". We’ll use a different statistical weighting procedure to address the same concern (details in the appendix). We’ll weight the performance of each pitcher who worked with a catcher in such a way that they contribute equal amounts to the overall variance of the catcher’s rating. We'll also see a new figure in the tables below -- Extra Runs Allowed (which we'll call XRA to distinguish it from ERA). XRA is simply the product of RPR and PA, and thus represents the number of additional runs the opposition would be score if the catcher was used instead of a catcher who performs like the composite of all the other catchers on the his team that season over the number of plate appearances the catcher actually caught. Negative numbers mean that the opposition scored fewer runs when the catcher in question would play. Positive numbers mean that the opposition would score more runs when the catcher was in the game. So, how do the catchers rank? The results may surprise you: Top 5 catchers per season by RPR, 1995-97 (min 1,000 PA caught) YEAR CATCHER PA RPR XRA 1997 Lopez,Javier 2742 -0.0360 -98.7 1997 Kreuter,Chad 1902 -0.0304 -57.8 1997 Girardi,Joe 2615 -0.0287 -75.2 1997 Oliver,Joe 2897 -0.0231 -66.9 1997 Difelice,Mike 2161 -0.0208 -44.9 1996 Piazza,Mike 2724 -0.0392 -106.8 1996 Walbeck,Matt 1620 -0.0325 -52.6 1996 Leyritz,Jim 1091 -0.0280 -30.5 1996 Santiago,Benito 2382 -0.0217 -51.8 1996 Hundley,Todd 1143 -0.0215 -24.6 1995 Mayne,Brent 2068 -0.0252 -52.2 1995 Macfarlane,Mike 1786 -0.0245 -43.7 1995 Myers,Greg 1117 -0.0230 -25.7 1995 Daulton,Darren 2068 -0.0178 -36.9 1995 Knorr,Randy 1205 -0.0171 -20.6 Note the huge numbers of runs in the XRA column. Worst 5 catchers each season by RPR, 1995-97 (min 1,000 PA caught) YEAR CATCHER PA RPR XRA 1997 Taubensee,Eddie 1251 0.0167 20.8 1997 Johnson,Charles 2667 0.0169 45.1 1997 Rodriguez,Ivan 3002 0.0265 79.6 1997 Posada,Jorge 1535 0.0276 42.4 1997 Wilson,Dan 1701 0.0410 69.7 1996 Pena,Tony 1359 0.0192 26.1 1996 Fletcher,Darrin 2504 0.0196 49.1 1996 Rodriguez,Ivan 3373 0.0234 79.0 1996 Girardi,Joe 1137 0.0292 33.2 1996 Servais,Scott 1670 0.0353 59.0 1995 Tingley,Ron 1144 0.0259 29.6 1995 Stanley,Mike 1443 0.0263 37.9 1995 Parrish,Lance 1405 0.0269 37.8 1995 Sheaffer,Danny 1271 0.0272 34.5 1995 Ausmus,Brad 1034 0.0319 33.0 Top 10 Catcher careers by RPR, 1981-97, (min 10,000 PA caught) NAME PA RPR XRA Kreuter,Chad 10859 -0.0148 -160.5 Skinner,Joel 12265 -0.0115 -141.4 Berryhill,Damon 11391 -0.0088 -100.8 Surhoff,B.J. 16827 -0.0086 -145.5 Dempsey,Rick 23108 -0.0082 -189.9 Martinez,Buck 10467 -0.0080 -84.0 Fisk,Carlton 30402 -0.0075 -228.0 LaValliere,Mike 21126 -0.0073 -155.0 Harper,Brian 13527 -0.0068 -91.8 Hassey,Ron 18935 -0.0060 -114.3 Worst 10 Catcher careers by RPR, 1981-97 (min 10,000 PA caught) NAME PA RPR XRA Steinbach,Terry 26575 0.0047 126.1 Cerone,Rick 22859 0.0053 120.4 Heath,Mike 25820 0.0053 136.3 Stanley,Mike 15058 0.0059 89.0 Ortiz,Junior 13599 0.0068 92.0 Bando,Chris 10202 0.0078 79.1 Flaherty,John 10253 0.0082 83.9 Petralli,Geno 10651 0.0089 95.1 Rodriguez,Ivan 16780 0.0103 173.3 Girardi,Joe 13675 0.0136 185.5 As with the battery combos, I looked at catchers' season RPR in consecutive seasons looking for some correlation. The conclusions were similar: of the 781 season pairs, the correlation in RPR from year N to N+1 was 0.01. Nor did dividing the catchers into above/below average groups show any persistent trend to remain above/below average. The following-season median RPR of the above and below groups were -0.001 and -0.002 respectively. In other words, the two groups were, again, almost identical in the following year. Though we would colloquially say that game-calling doesn’t exist, it’s more accurate to say that if there is a true game-calling ability, it lies below the threshold of detection. There is no statistical evidence for a large game-calling ability, but that doesn’t preclude that a small ability. For example, a genuine game-calling ability that reduces a pitcher’s ERA by 0.01, resulting in a savings of about 1.6 runs per year for the entire team and could be masked by the statistical variance in the sample size we have to work with. Players would need to play thousands more games than they actually do to have enough data to successfully detect such a skill statistically. There are other places to look for a catcher’s influence beyond the game-calling ability looked for in this study. A catcher might be able to impact the "clutch" performance of the pitcher, helping him focus in high leverage situations. Such a pitcher would surrender fewer runs than expected from his hits & walks allowed. A catcher who senses what his pitcher is throwing well might be more efficient in calling pitches, reducing the pitch count per batter, and thus allowing the starter to go deeper into the game and preserving the bullpen. Nothing in this study precludes any of the possibilities from being true, and this is a promising line for future investigation. However, if we believe the results from this study, namely that catchers do not have significant differences among their game-calling abilities, the implications are staggering. First of all, the much-maligned stats we’ve been using for years to evaluate catchers--runners thrown out and passed balls, might actually quantify their defensive value. Furthermore, the relative unimportance of the running game could prompt teams to shift better offensive players to catcher without hurting the team’s defense. You open up another position on the field besides first base for prospects who don’t have the reflexes to play the infield, nor the speed or instincts to play the outfield. The positional is still physically demanding to play, but you could potential keep two dynamite offensive players in the lineup--say Mike Piazza and Frank Thomas, but swapping them between C and 1B so neither gets overworked behind the plate. Far from being the position with the lowest expected offense, it could flip to the other side of the defensive spectrum entirely, and become a place to hide a slow-footed slugger. Even though our foray into Z scores, RPR and XRA have led us to conclude that catcher game-calling isn't a statistically significant skill, I'm well aware that many of you will want to see the results for your favorite catcher, or to review how other catchers measured up. I've listed seasonal and career RPR and XRA for most catchers in the appendix. Just keep in mind that the results are almost certainly due to randomness rather than aptitude. This research would not have been possible without the generous assistance and contributions of several other people. Thanks to Tom Fontaine for his help in extracting the pitcher-catcher splits. Thanks to Phil Beineke of Stanford’s Statistics Department for his consulting, advice, and patience, particularly with the computation and analysis of the weighted averages and Z-scores. Thanks to Baseball Workshop/Total Sports, and to Retrosheet for making the data available for this kind of work. And most of all, thanks to my wife, Kathy, who’s been making do without a husband for most of the past two months.
Appendices
Keith Woolner is an author of Baseball Prospectus.
|