
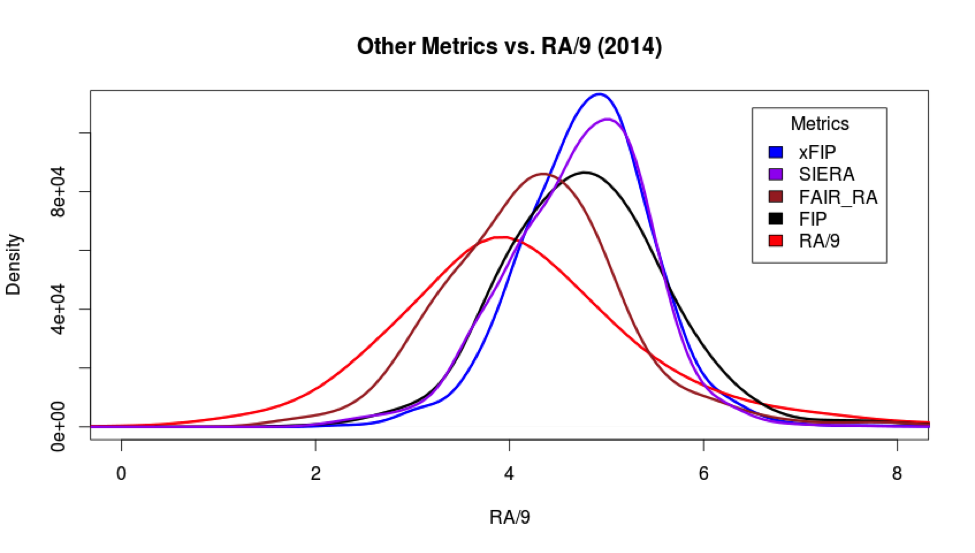
 This plot is weighted by the number of batters faced, and includes all pitchers from the 2014 season. It shows the weighted density plot for the values of xFIP, SIERA, Fair_RA, and FIP as compared to underlying RA/9. (We adjusted xFIP, SIERA, and FIP to an RA/9 scale as they were designed originally for ERA.) RA/9 is the red line, and as you can see, the other metrics fit RA/9 fairly poorly. In fact, none of them are that close.
This plot is weighted by the number of batters faced, and includes all pitchers from the 2014 season. It shows the weighted density plot for the values of xFIP, SIERA, Fair_RA, and FIP as compared to underlying RA/9. (We adjusted xFIP, SIERA, and FIP to an RA/9 scale as they were designed originally for ERA.) RA/9 is the red line, and as you can see, the other metrics fit RA/9 fairly poorly. In fact, none of them are that close. Just a slight difference. Despite using previous seasons’ data as its basis, DRA smoothly describes the current season’s RA/9 substantially in tune with the actual runs a pitcher gives up, while still making the contextual adjustments that blame the pitcher only for runs that are most likely to be his fault.
Just a slight difference. Despite using previous seasons’ data as its basis, DRA smoothly describes the current season’s RA/9 substantially in tune with the actual runs a pitcher gives up, while still making the contextual adjustments that blame the pitcher only for runs that are most likely to be his fault.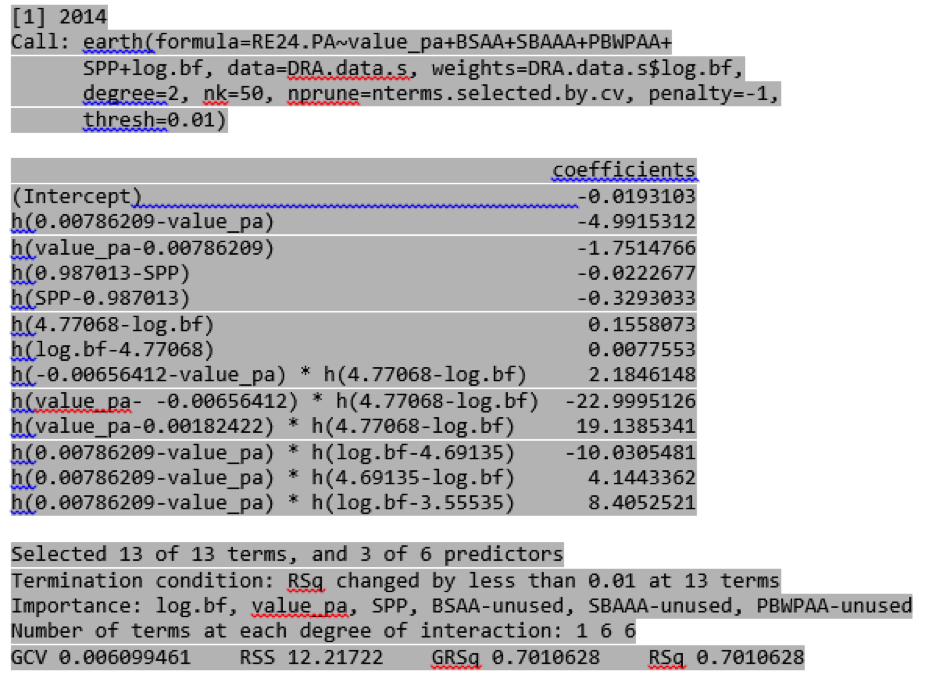
 16 comments have been left for this article.
16 comments have been left for this article. BP Comment Quick Links

|

|
April 29, 2015 Prospectus FeatureDRA: An In-Depth DiscussionThis is the #GoryMath portion of the DRA rollout. If you proceed, don’t say we didn’t warn you. A. Introduction This is particularly important when it comes to pitcher performance metrics. What is it, exactly, that you want to know? For example: (1) Do you care primarily about a pitcher’s past performance? (2) Are you more worried about how many runs the pitcher will allow going forward? (3) Or do you want to know how truly talented the pitcher is, divorced from his results this year or next? The reader’s likely response is: “I’d like one metric that excels at all three!” Sadly, when it comes to composite pitcher metrics, this might not be possible. Earlier this month, Jonathan published an article in the Hardball Times entitled “FIP, In Context,” which discussed the challenge of descriptive versus predictive pitcher estimators. The article used mixed models to generate a new statistic—cFIP—that appears to be superior at answering questions (2) and (3), despite considering only a pitcher’s strikeouts, walks, and home runs allowed. But even cFIP, despite its edge in predicting future scoring and pitcher talent, could not compare to other metrics when asked to describe past events, the subject of question (1) above. The article offered this table: Table 1: Descriptive Power, In-Season
The table compares the ability of each metric to describe the same-season performance of all pitchers, as correlated to their RE24/PA. On this scale, a score of -1 was best and 0 was worst. RA/9 and ERA do best, because those metrics just count the runs that crossed the plate. cFIP, however, did poorly by comparison. Why? Because so much of what occurs on a play operates beyond the player’s true talent. Events are driven not only by talent, but by circumstances and random variation. Properly describing past events therefore requires a metric able to “overfit” the pitcher’s talent so that actual outcomes are being considered as well. We know that good descriptive metrics, including RA/9 and ERA, essentially overfit the pitcher’s talent because their next-year predictive performance is so poor by comparison: Table 2: Season-to-Season Reliability
This table is almost a reverse of the first, again showing all pitchers for these seasons. It shows the consistency with which a pitcher’s score on a metric in one season will match their score in the next season. A “1” is the highest score, and 0 is the worst. As you can see, both ERA and RA/9 are worthless in predicting next year’s run expectancy for a pitcher. If you are interested in predicting a pitcher’s next-season or rest-of-season performance, that’s when you should be using cFIP. It also means that if we want to fairly describe what has already happened with a pitcher on the mound, we need to try something else. And that is the challenge. If we limit the blame to the pitcher’s true talent—using only cFIP or something like it—we leave a massive amount of unexplained variance that, like it or not, still happened while that pitcher was on the mound. On the other hand, if we go strictly by runs that scored with the pitcher in the game, then the pitcher gets blamed for everything. This distinction is particularly important when calculating Wins above Replacement (WAR), or as we call it here at Baseball Prospectus, Wins above Replacement Player (WARP). We believe that a reasonable compromise between these two extremes is what we call “fair responsibility.” In-game events are, again, a combination of talent plus circumstances plus random variation. Events that may not be a pitcher’s “fault” are nonetheless influenced by him. The path to evaluating fair pitcher responsibility—and thus, a proper measure for pitcher WARP—lies in recognizing not only that the events in fact occurred, but by making reasonable adjustments for other contributing factors. Very few people will disagree with that principle as stated. The question is how you implement it. There seem to be two general approaches. Our friends at Baseball Reference use what we would call a “reverse” approach: they start with pitcher runs allowed per nine innings, and work backward to determine how many runs an average pitcher would have allowed under similar circumstances. To do this, they adjust for factors like overall strength of opposition, the average defense behind the team’s pitchers, and the parks in which the pitcher threw. They then determine the number of runs that an average pitcher would be expected to allow under similar circumstances, and calculate the wins a pitcher was worth. A discussion of Baseball Reference’s method for its Wins above Replacement metric (a/k/a “bWAR”) can be found here. The second, or what we would call the “forward” approach, is used both by our friends at FanGraphs and by us here at Baseball Prospectus. The hallmark of the “forward” approach is that, rather than working backward from runs allowed per nine innings, you instead start from scratch and look for factors that correlate well with runs allowed. The more (reliable) factors you incorporate, the closer you get to predicting current-season runs allowed by a pitcher. Until now, we at Baseball Prospectus have been using Fair Run Average (also known as FAIR RA or FRA) as our runs estimator for pitcher WARP. FanGraphs uses Fielding Independent Pitching (FIP), and then makes additional adjustments for run environment and the parks in which the pitcher threw. A discussion of FanGraphs’ method for its Wins above Replacement metric (a/k/a “fWAR”) can be found here. Although the “reverse” approach is reasonable, we have decided to stick with the “forward” approach to estimating pitcher value with our new metric, Deserved Run Average (DRA). We are doing this for a two reasons. First, we are concerned that under the “reverse” approach, any variance that cannot be explicitly accounted for is, by default, assigned to the pitcher. Because the outcome of a baseball event usually stems from the contributions of (and interactions between) multiple actors, this assumption strikes us as problematic. By contrast, under the “forward” approach, unexplained variation is essentially divided up: no one participant, and certainly not the pitcher, is tagged with the entirety of the residue. Second, we believe that the “forward” approach gives us more control over the metric. When combined with the contextual adjustments we are making to each event, we think we are able to provide the best of both worlds. We believe that DRA is a superior metric for evaluating pitcher responsibility, both as the basis for pitcher WARP and for determining how well a pitcher in fact pitched in a given season (or over his career). We’ll now go into detail why we feel that way. B. The Method 1. Tabulating and Assigning Event Value The first part is easily the most important. We need to account for every batter event in baseball, we need to note the relevant participants in it, and we need to assign the proper linear weight to that event. The table of linear weights we use is dynamically adjusted for each season. Here are the primary events for the 2014 season: Table 3: 2014 Linear Weights (subset)
2. Modeling Contextual Adjustments to Event Responsibility Next, we take each event and model the factors that contributed to it. To do this, we use a linear mixed model that both (a) assigns credit (or blame) for the tendency of each type of participant to be involved in each type of event, and (b) controls for environmental factors that could influence the outcome of the event. We then tabulate the total predicted effect of each pitcher on run expectancy, as compared to the total effect without that pitcher being involved, and divide that number by the total number of batters the pitcher faced. We call this interim output value/pa, and it is the primary driver of the pitcher’s ultimate DRA. The underlying equation for this model is as follows: value.model<- lmer(lwts ~ bats + inning*score_diff + start_bases_cd*outs_ct + csaa + temp + stadium + PF + role + fraa*bat_home_id + inning*bat_home_id + (1|batter) + (1|pitcher) + (1|catcher) + (1|umpire), data=value.data.s) This equation is rendered in R using the lme4 package. For the various types of batter events, we found that the batter, pitcher, catcher, and umpire were the participants of note. (Umpires are only currently used from 1988 onward). The lmer function calculates the most probable effect each of them had, in the aggregate, on run expectancy over the course of a given season. The pitcher values, divided by the numbers of batters faced, equal the pitcher’s value/pa. Likewise, we controlled for several environmental factors. The variable bat_home_id controls for home team bias. The variable bats controls for batter handedness. The interaction of inning and score differential recognizes that both base running and the approaches of hitter and pitcher can be influenced by the closeness of the score and the inning of the game. Similarly, start_bases_cd*outs_ct controls for the base-out state of the event. Participants behave differently with no outs than they do with two outs, and with a runner on third versus the bases empty. Stadium is simple enough: certain stadiums are particularly conducive (or resistant) to certain types of hits or other events. As you will see below, we already account for overall stadium environment through park factors, but separately accounting for stadium both improved the model and accounts for in-season aberrations. Then, things start getting interesting. The variable fraa stands for our defensive metric, Fielding Runs above Average (FRAA), which rates the quality of the defense on the field behind the pitcher. We actually determine this individually for each event, instead of just taking a seasonal average. To do this, we total up the seasonal FRAA values to date for each defender in the field (excluding catcher) and account for them on each individual play. If a pitcher happens to have a particularly capable (or incompetent) defense behind him on a particular play, the model can account for that. Likewise, we incorporate the effect of catcher framing. As far as we know, this is a first, both in pitcher metrics and in calculating Wins above Replacement. A few months ago, we introduced Called Strikes above Average or CSAA, which rates all catchers by their framing ability. By controlling for the framing ability of the catcher behind the plate, we can help control for the pitcher’s likelihood of ending up in more or less favorable counts by his catcher. Our csaa variable also accounts for the umpire’s strike zone and the effect of the particular batter upon the likelihood of called strikes in each at-bat. Particular batters may be of unusual stature or benefit from reputation, so it makes sense to control for them. The csaa variable for each event is the net effect of all these actors involved. CSAA is available for events beginning in 1988. Lastly, beginning in 1998, we account for game-time temperature[1]; park factor by handedness (PF) which accounts for the overall tendency of each ballpark to favor left or right-handed hitters; role, which accounts for the fact that life is easier as a reliever than as a starter; fraa*bat_home_id, which recognizes that teams play defense better in their home park; and inning*bat_home_id, which accounts for the fact that in later innings, the home team is more likely playing for only one run. In 2014, the highest value/pa came from the following pitchers: Table 4: Top 5 Value/PA, All Pitchers, 2014
The scores for value/pa are numbers above (or below) zero, which is major-league-average. We’ve converted them to percentages here for easier viewing.
3. Accounting for Base-Stealing Activity We described the rationale for Swipe Rate Above Average (SRAA) and Takeoff Rate Above Average (TRAA) in the Overview article. We won’t repeat those here. We will, however, show you what both model equations look like. Both models use a generalized linear mixed model. Here is the Swipe Rate comparison model: success.s <- glmer (success ~ inning + stadium + cFIP + (1|pitcher) + (1|lead_runner) + (1|catcher), data=success.data, family=binomial(link='probit'), nAGQ=0) We found that the inning of the stealing event was more important to its success than the score of the game, which we removed from the model. Starter versus reliever did not seem to affect base-stealing success, so that variable was removed as well. We again accounted for stadium and used cFIP—which is now posted here at Baseball Prospectus as a true talent metric for pitchers—to control for pitcher quality. Controlling for pitcher quality is useful because bad pitchers could mitigate the need to steal, whereas good pitchers can make runners who get on base more desperate. In terms of participants, we found that the identity of the pitcher, lead runner, and catcher were all important in determining the likely success of a stealing attempt. On average, catchers were about twice as important as pitchers in determining whether a base would be successfully stolen. The identity of the lead runner, in turn, was twice as important as the catcher in predicting stolen-base success. For TRAA, the model was a bit more complex. Here, we are focusing on pitchers who tend to inspire (or deter) base-stealing attempts regardless of success. Our view is that TRAA could correlate with the number of steps a runner is willing to take off the bag, thereby affecting the likelihood of successful double-plays and taking extra bases. Here is our model for the Takeoff Rate comparison: attempts.s <- glmer (run_attempt ~ inning * score_diff + stadium + lr_SRAA + c_SRAA + start_bases_cd*outs_ct + cFIP + role + (1|pitcher) + (1|batter) + (1|lead_runner) + (1|catcher) + (1|ondeck), data=attempts.data.s, family=binomial(link='probit'), nAGQ=0) For TRAA, the interaction between inning and score differential is back, because steal attempts depend heavily on the closeness of the score and the lateness of the inning. Stadium is included again, to help account for field conditions. We then imported lead runner SRAA and catcher SRAA from the SRAA model, because the lead runner’s ability to steal bases and the catcher’s ability to throw them out obviously affect the decision to attempt a steal. We also controlled for base-out state (start_bases_cd*outs_ct), pitcher quality (cFIP), and starter versus reliever (role). We also added one additional participant, because we found that the identity of the hitter on deck slightly influences the decision of whether a steal is attempted or not. We started tracking the on-deck hitter in 2011, so for now, only values from 2011 through the present time include this predictor. We’ll try to take it back in time later. We also considered adding the identity of the hitter in “the hole,” but it made no difference. One particularly interesting observation from our model: when controlling for pitcher quality (cFIP), starter versus reliever (role), and the other factors, the pitcher, on average, was substantially more important (in fact, more than an order of magnitude more important) than the catcher in determining whether a base-runner would attempt to steal or not. So, when people say that baserunners generally try to steal off the pitcher? They’re almost certainly right. 4. Other Inputs At this point, most of the heavy lifting has been done, in terms of inputs. However, we generated a few more. First, we created a mixed model passed ball/wild pitch metric for pitchers, although we only applied it from 2008 to the present, because the model relies on PITCHf/x data. You can consider this an update from the Regressed Probabilistic Model that was introduced last year, much like CSAA was an upgrade from the RPM/WOWY method for catcher framing. We called this Errant Pitches Above Average (EPAA). That model is specified as follows: pbwp.2014 <- glmer(pbwp ~ log(pbwp_prob) + (1| catcher) + (1|pitcher), pbwp.data, family=binomial(link = "probit"), nAGQ = 0) This model is quite simple, and it only converges by including a log transformation of the PBWP probability (which is based on PitchInfo data). For pre-2008 seasons, we used a simple With or Without You (WOWY analysis), because the model will not converge satisfactorily with the information available. Second, we decided to take into account the percentage of each pitcher’s events that occurred in a starter capacity versus a reliever capacity. There is no magic to this calculation: it is straight math, and we call it Starting Pitcher Percentage, or SPP. People who served solely as a starter rate at 100 percent, or 1, those that were pure relievers will be 0, and those who had a mixture will be .2 or .6 or whatever their percentage of batters faced as a starter happens to be. C. The DRA Calculation What is the best way to model this relationship? That required a lot of testing. A LOT of testing. We tried linear models. We tried local regression. We tried tree-based methods. We bagged the trees. We tried gradient boosting. We tried support vector machines. We even tried neural networks. None of them were providing better results than existing estimators. And then we tried the one method that turned out to be perfect: MARS. MARS stands for Multivariate Adaptive Regression Splines, and was introduced by Dr. Jerome Friedman of Stanford in 1991. You don’t hear much about MARS anymore: it has been supplanted in the everyday modeling lexicon by trendier machine-learning methods, including many of those we mentioned above. But MARS, in addition to being useful for data dumpster-diving, also has another big advantage: interactions. MARS uses what are known as regression splines to better fit data. Instead of drawing a straight line between two points, MARS creates hinges that allow the line to bend, resulting in “knots” that accommodate different trends. The power of these knots is enhanced when MARS looks at how variables interact with each other. These interactions are, in our opinion, one of the under-appreciated facts in baseball statistics. As discussed above, pitchers who are pitching particularly well or poorly have a cascading effect on other aspects of the game, including base-stealing. Moreover, there is a survival bias in baseball, as with most sports: pitchers who pitch more innings tend to be more talented, which means they end up being starters instead of relievers or spot fill-ins. The power of MARS is it not only allows us to connect data with hinged lines rather than straight ones, but that it allows those hinges to be built around the most significant interactions between the variables being considered, and only at the levels those interactions have value. MARS also uses a stepwise variable selection process to choose only the number of terms sufficient to account for the most variance. Dr. Friedman licensed his code to Salford Systems, including the name MARS. But the equations published in his articles are in the public domain, and various authors have published freeware versions that take advantage of it. In R, the easiest package to use is called earth. Here is the general earth equation we used for each season: DRA.model.s <- earth (RE24.PA ~ value_pa + SRAA + TRAA + SPP + ERAA + log.bf, data=DRA.data.s, nk=50, weights=DRA.data.s$log.bf, degree=2, nfold=10, ncross=100, thresh=.01) The earth model fits the best relationship between RE24 per plate appearance (RE24.PA) and the various predictors we have developed: value_pa, SRAA, TRAA, PBWPAA, and SPP. It also uses one other predictor that had been hiding in plain sight: bf (batters faced), which is the same as plate appearances. Including bf in the model improves its accuracy, perhaps because it helps account for survival bias. A tolerance check showed the predictors to be substantially independent from each other (tol. >=.61). In earth’s unique lexicon, the “degree” tag authorizes use of interactions, not polynomials. To train the model for a given season, we considered using the prior season, the prior two seasons, and the prior three seasons. The winner was the above model, which includes bf as a predictor, is also weighted by bf, and relied upon the prior three seasons of all pitchers for model training. Using the previous three seasons for training helps smooth out one-year aberrations and better fit the run environment. The superior results of this approach, discussed below, support its usage. In choosing the training data, the goal was to establish the relationship between our predictors and run expectancy, not to look at particular pitchers. So, we didn’t weight any one season heavier than any other (as is often done in projection systems), because all three seasons were viewed as part of the same run environment. After some discussion, we also elected not to “cheat” by using past production from certain pitchers to predict their individual future performances. DRA is not a projection system: it is a pitcher quality estimator. We’ll get to the projection part in time. MARS includes variable selection, so we used 10-fold cross-validation, repeated 100 times, to choose the optimal number of terms for each season. D. The Results We provided a sample of our scoring system in the overview article. Here, we will describe it in somewhat greater detail. Again, our objection here is to be descriptive; that is, to accurately characterize the pitcher’s fair responsibility for the runs that scored on his watch, while still being predictive of the overall runs allowed. The DRA model therefore “predicts”[2] what the pitcher’s “deserved” runs allowed ought to be in the current season. To convert that prediction into a final equivalent of runs allowed per nine innings, and convert plate appearances into innings pitched, we apply this formula: DRA.s$DRA.raw <- ((predict(DRA.model.s, DRA.s) * DRA.s$bf / DRA.s$outs * 27 )) The pitcher’s actual DRA comes by adding the raw DRA value to the constant necessary to put DRA onto the RA9 scale. We use the pitcher’s own season-to-date batters-faced-to-outs ratio to make this conversion, rather than a league-average conversion rate or an equation based on the underlying events. One of our thoughtful reviewers was concerned that using personal ratios would make the results too volatile, but after further investigation, we think it is the right approach. Using a pitcher’s own bf-to-outs ratio underscores our belief that pitchers help create their own run environment. More importantly, we charted the correlation of value_pa to RA/9 over the first two months of the 2014 season, and found that value_pa and RA/9 maintained a steady relationship. This confirms that using individual bf-to-outs ratios is appropriate, at least with the contextual adjustments our models make. The test of DRA, then, comes on its ability to predict actual runs allowed by the pitcher. And that is something DRA does exceptionally well, better than anything else in the public domain right now: Table 5: Average Metric Descriptive Performance, 2011-2014
This chart averages the descriptive performance of Fair Run Average (FAIR_RA), FIP, and DRA from 2011 through 2014, using four different measures of prediction: Root Mean Squared Error (RMSE), Mean Absolute Error (MAE), the Spearman Correlation, and the weighted Pearson Correlation. We want the lowest scores on the error measures, and the highest scores on the correlation measures. It really makes no difference which metric you consider. In every measure, and in every tranche of pitchers, DRA is the clear and consistent winner. As we mentioned in the separate Introduction article, FIP accounts for about 50 percent of the variance in pitcher performance (.702). DRA, on the other hand, accounts for about 72 percent of the variance in pitcher performance (.852). That is a significant improvement. This also means that DRA is doubly valuable as a measure of pitcher performance. We already know that DRA adjusts meaningfully for a wide variety of confounding factors that are not the pitcher’s fault. It also adjusts for the effects of other participants involved in each play. The fact that DRA also, at the end of the day, still better predicts a pitcher’s overall runs allowed brings its success full circle. DRA appears to be measuring pitcher value both fairly and accurately. DRA is a clear and convincing improvement over the alternatives, including what we at BP have been using to date. E. The Secrets of DRA’s Success Why does DRA perform so well? Aside from what we would like to think is its sound design, there are three aspects of DRA that deserve special mention. The first is that DRA, as you would expect from its excellent test scores, fits the distribution of RA/9 much better than other pitcher run estimators. Here, for example, is the fit of several competing estimators, as compared to RA/9, for the 2014 season:
Contrast that with the fit between DRA and RA/9 below:
The second reason DRA does so well is because it is a dynamic model, rather than a static formula. Before each season, the DRA earth code generates a new model based on the relationship it derives between its predictors and run expectancy over the previous three seasons. Thus, as the run environment changes over the years, the DRA model automatically adjusts. In addition to drawing from the updated linear weights for each season, DRA has the freedom to select which combination of the six predictors best model the current run environment. In many cases, it declines to use certain predictors at all. For example, in 2014, DRA was satisfied to use three of the six predictors: value_pa, SPP, and batters faced. In other years, we have seen as many as five predictors used. Value/PA and batters faced are consistent favorites, but different run environments benefit from different combinations. The earth model’s enthusiasm for deriving interactions can be shown in the following table, which lists the various coefficients the model derived for predicting pitcher DRA in the 2014 season:
The third and perhaps most interesting reason for DRA’s success is that mixed modeling sidesteps one of the most challenging aspects of pitcher quality estimation: batted ball data. Many researchers tear their hair out trying to reconcile differing reports of line drives versus fly balls versus ground balls from different stringers in different parks reporting to different statistical bureaus. One would think that DRA, by taking into account events involving balls in play, would basically collapse on itself, or max out at a very poor rate of performance. And yet that is not the case. What DRA does instead is to use the identities of the pitcher and batter as proxies for their batted ball tendencies. To the extent any batter or pitcher in fact has a batted ball profile, that profile is reflected in their performance and particularly in their interactions with other players. DRA can’t tell you specifically whether pitchers are giving up line drives or fly balls, and frankly it doesn’t care: by accounting for the performance of batters and pitchers against each other, and the environments in which those matchups take place, DRA skips right to the answer, without getting tangled up in the wrong question. Having concluded the superlatives, we’ll throw in two notes of caution. First, to bring us back to the topic that opened this article, DRA, like all statistics, is best used only as intended. DRA is a superior metric for evaluating past pitcher performance and upon which to build a concept of pitcher wins. It is not, however, intended to be predictive, and our testing suggests that while it is better than pure RA/9 (not surprisingly) in that regard, it is still ill-suited for that purpose. Again, if pitcher true talent is what interests you, use cFIP. If a detailed assessment of future performance interests you even more, use PECOTA or something like it. Second, like other statistics, DRA has a bit of a ramp-up period. This manifests itself in two ways. Initially, it takes about nine or 10 games before there is enough data in a season for the contextual adjustments to function meaningfully, and as with other baseball metrics, the more data it has to work with, the better. So, in the beginning of any season, you should expect a delay of about two weeks before DRA starts posting. Also, even when it starts generating data, most of it comes at first from value/PA as opposed to other aspects. So, as mentioned in the Introduction article, for the first month or two we will only use value/pa to generate DRA, and will switch over to the full model later. Our testing indicates that taking this approach generates the same ranks between pitchers (via Spearman), but less extreme values between them (via the Pearson weighted correlation). F. Conclusion You can currently find DRA, cFIP, and PWARP_DRA here: We hope you will share your comments and suggestions. Special thanks to Rob McQuown for research assistance; to Dan Turkenkopf, Harry Pavlidis, Rob Arthur, Rob McQuown, and Greg Matthews for their collaboration; to Stephen Milborrow for modeling advice; and to Tom Tango and Brian Mills for their review and insights. Bibliography Bates D, Maechler M, Bolker B and Walker S (2014). lme4: Linear mixed-effects models using Eigen and S4. R package version 1.1-7, [http://CRAN.R-project.org/package=lme4] R Core Team (2014). R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria. URL http://www.R-project.org/. Stephen Milborrow. Derived from mda:mars by Trevor Hastie and Rob Tibshirani. Uses Alan Miller's Fortran utilities with Thomas Lumley's leaps wrapper. (2015). earth: Multivariate Adaptive Regression Splines. R package version 4.2.0. http://CRAN.R-project.org/package=earth. Other resources were linked as indicated. [1] We replaced extreme temperature outliers (< 20 degrees, > 110 degrees) with the median values, as they were almost certainly wrong as described. There were only a few of these entries each year. [2] Our use of the term “predictive” here may seem confusing, as people generally use the term “predictive” to describe future performance. However, it is important to remember that all model outputs are “predictions,” and that includes predictions of what a pitcher’s past performance ought to have fairly been, accounting for circumstances.
Jonathan Judge is an author of Baseball Prospectus. Follow @bachlaw
|
This all seems excellent. I have a general question about FRA (and all models generally).
Why are they all slightly skewed to the right? Is there something inherent to each model that would account for this that I don't understand, or is this just a coincidence?
It's a great question. I think they all tend to skew toward the mean because of the preference to be predictive to some extent, and all players regress toward the mean.
Others may have thoughts on this too.