








 33 comments have been left for this article.
33 comments have been left for this article. BP Comment Quick Links

|

|
February 5, 2015 Moving Beyond WOWYA Mixed Approach To Measuring Catcher FramingLast year, Baseball Prospectus introduced our Regressed Probabilistic Model (or “RPM”) for catcher pitch-framing. RPM uses PITCHf/x data to increase the measured accuracy of the actual contributions made by catchers. But RPM also suffered from two limitations. First, because PITCHf/x data was not publicly available before 2008, RPM could only measure catcher framing from recent seasons. Second, it relied primarily on a piecemeal approach to identifying the individual contributions of pitchers, umpires and catchers. This year, we are pleased to announce an improvement that will address both limitations. We propose to move RPM from a “With or Without You” (WOWY) comparison method to a mixed model we call “CSAA” —”Called Strikes Above Average.” This new model allows simultaneous consideration of pitcher, catcher, batter, umpire, PITCHf/x, and other data for each taken pitch over the course of a season, and by controlling for each of their respective contributions will predict how many called strikes above (or below) average each such participant was worth during a particular season. Although PITCHf/x data is preferable when available, the mixed model (in a revised, “Retro” form) will allow us to live without it when need be, permitting us to project regressed framing of catchers all the way back to 1988, when pitch counts were first officially tracked.[1] This same technique developed for Retrosheet can also be applied to recent minor-league data to provide an even deeper view into the progression and value of this skill. We’re excited to tell you what a mixed model can do and some of the insights it gives us on catcher framing. But, in addition to telling you what we’ve found, we’re going to spend a fair amount of time telling you what we did and how we did it. We want to explain in detail how mixed models can help with sports modeling, and why we think they need to start being used more often. In particular, we are hoping for your feedback. Baseball Prospectus has some of the smartest readers in the industry. Mixed models are under continued study and development in the statistical community. By working together, we can develop a better, shared understanding of how mixed models work in the sports context, to the ultimate benefit of all. Background The second part of RPM is not proprietary: it is known as With or Without You (“WOWY”), and it rates catchers by comparing their production to others receiving the same pitchers. So, we compare the performances of pitchers and catchers to those of their battery-mates when they work with other catchers and pitchers, and look for differences in performance. WOWY was popularized by Tom Tango, who found that, by using Retrosheet data, he could compare the success rates of different catchers at preventing PBWP. Tango extended the concept to players on the field, using the shortstop put-out rates for Yankees pitchers to confirm that Derek Jeter, even in his prime, was a subpar defensive shortstop. Since Tango published these articles, WOWY has become a generally accepted method of comparing players, particularly for catcher metrics. WOWY works reasonably well. As we discussed last year, the results, particularly when combined with the probabilistic model, made intuitive sense and confirmed the reports of trusted scouts as to who the best catchers were. But WOWY has acknowledged limitations too. Within a particular season, each player is typically compared to others playing for the same team. This means that a starter is usually being compared to his backup, who is a backup for a reason. This problem can be compounded with what Tango has labeled the Cal Ripken effect, which can arise when the starter plays so much that his backup’s sample size isn’t large enough for meaningful comparison. And above all, WOWY tends to operate in a two-way vacuum: It’s all well and good to see how a catcher did with certain pitchers, and vice versa, but how should we incorporate the umpires who were calling those pitches, and the batters who were motivating particular pitches? What if one tandem was playing in a particularly difficult division or its schedule was unusual? Beyond the limitation of two-way comparisons, there is the equally important issue of regression: the reality that no player at a given time is actually displaying his true talent. Figuring out where that true talent lies, in turn, is difficult to do without an understanding of how league participants, as a whole, tend to affect plays when placed in comparable positions—not only as catchers and pitchers, but in front of different umpires and batters. RPM does have a regression component, but ideally the regression would be simultaneously applied to all participants at the same step of the analysis. We believe the solution, or at least the next step forward, lies in the so-called “mixed model” approach. We are not the first people to suggest this idea. Max Marchi wrote about it a few times, and provided some estimates of how various players would rate. But Max then took his talents to Huntington Beach (or thereabouts), and the idea has not publicly been explored further. We think the time has come for mixed models to become an accepted part of everyday sabermetric analysis. Specifically, CSAA is based on a generalized linear mixed model, which we propose to take the place of WOWY for future catcher framing comparisons. CSAA allows us to put each participant’s performance into context and simultaneously impose regression both “within” subjects (regressing individual players toward their true talent from outlier performances) and “between” subjects (regressing performances as a whole toward the mean major-league average). CSAA also gives us the flexibility to model catchers both from the PITCHf/x era (2008 to the present) and the recent past (1988 through 2007) during which ball-strike counts were officially tabulated. We call this “CSAA-Retro.” We will apply it to the minor leagues as well. A brief amount of Gory Math™ lies ahead. You can rejoin the fray after this section if you’re a bottom-line sort. Mixed Models: An Introduction If you’ve gotten this far, you’re probably familiar with the equation for a line: y = mx + b On a two-dimensional graph, the “y” is the distance up or down from the zero on the vertical (y) axis; the “x” is the point to the left or right of zero on the horizontal (x) axis; the m is the slope of the line that connects x and y on a graph, and b is the “intercept” — the point at which the line actually crosses the y axis. This equation of a line is the essence of a simple linear model, in which values for x are used to predict values of y. However, when we predict, we make errors. In fact, virtually all of the predictions from any model are “wrong” in the sense that they are slightly off from the true value. Updating our equation, and again keeping it as simple as possible, we come up with this: y = mx + b + E We’ve now added an error term: (“E”). Simple linear regression—the concept implemented by a linear model—uses this formula to generate predictions of y for each value of x. The E is the sum of the collected distances of each y point from the predicted line (the errors). The reason E is left out of standard equations because it is assumed that all errors will cancel each other out, and it is therefore redundant. Linear regression assumes that these collective errors are not only zero-sum, but also independent from one another. However, this additional assumption is sorely tested in sports modeling. There is a great deal of interdependence in baseball events. The same batters face the same pitchers, with the pitches received by overlapping catchers, all the while having balls and strikes called by a rotating stable of umpires. These events are not independent. Interactions aside, we have hundreds or thousands of in-game events involving each individual player. Obviously, multiple measurements from the same player are not independent from one another: we expect good players to be consistently above average, and bad players to be consistently subpar. Traditional, single-level models—regardless of form—ignore these factors, sometimes at their peril. Mixed models, however, have a place for these interrelated error terms. They are called “random effects.” They are distinguished from “fixed effects,” which are the ordinary “x” variables you see in your typical line equation. The distinction between fixed and random effects is somewhat fluid, but the fixed effects generally have defined levels that are not affected by the number of observations in the sample. So, regardless of how many plate appearances you are considering, there is a maximum defined number of ball-strike counts, and only a two hands a pitcher can use to pitch. The categories of “count” and “handedness,” therefore, are fixed effects. On the other hand, there are a potentially unlimited number of pitchers, catchers, and other participants that can play over a season or seasons. Thus, participants in a sporting event are better modeled as “random effects”: their individual contributions, and the relationships between them, would otherwise be written off as “error” in a single-level model. The mixed model not only accounts for them, but puts them to good use. In the statistics literature, random effects were originally viewed as pollutants: a factor to be controlled so that the statistics truly of interest—the fixed effects—could be isolated without contamination. But people started noticing it might be useful to quantify random effects and thereby determine the individual contributions of subjects participating in their experiments. This is particularly true in the area of educational assessment. There are often fixed effects we want to consider when evaluating the performance of a school: student economic status, geographic location, and available resources. But there are also random effects that confound these results: different teachers, different school districts, and of course the schools themselves. In the lingo of mixed models, these types of random effects are both “crossed” and “unbalanced”: they are “crossed” because we have teachers, students, school districts, and schools interacting with one another, and they are “unbalanced” because the students, school districts, and teachers usually are not equally experiencing each other. With mixed models, this makes no difference: each random effect is taken into account to the extent of its contribution and the extent of its effect on the other variables. The usefulness of mixed models in sports statistics, we think, should be clear. A typical regression predicts an average outcome over the course of a season for all participants in a category, ignoring the interrelationships between participants. Alternatively, we look at individual participants and try to separately regress their achievements. Both methods can yield reasonable results. But, wouldn’t it make more sense to solve for them simultaneously, letting both levels of the analysis borrow strength from each other? That is what mixed models are all about. Using a mixed model, we can solve for the average, league-wide effect of the variables at the fixed effect level of the equation. At the random effects level of the same equation, we can simultaneously isolate the most likely individual contributions of each participant: batters, pitchers, catchers, umpires, and anyone else of interest, at all times controlling for their relative effects on each other. A Mixed Model for Pitch Framing The specified details of the CSAA mixed models are in the Appendix. The Reader’s Digest version is as follows: the model considers each and every pitch thrown in the major leagues each season. For each pitch where a batter did not swing, we input (1) whether the pitch was a ball or strike (our output variable), (2) our various participants: the pitcher, catcher, batter, and umpire, which are our “random effects”; and (3) our chosen “fixed effects” we found to be meaningful: the PITCHf/x probability of the pitch being strike, the handedness of the pitcher and batter, and whether the team was playing at home or away. All of these fixed effects have a statistically significant effect on the likelihood of a pitch being a strike. For CSAA, we ran the model separately for each season from 2008 to the present time, and collected each season’s results. Hello Gory Math skippers! Welcome back... Here are the top- and bottom-five catcher framers for the 2014 season according to the CSAA model, along with their corresponding values under the existing RPM method, and the differential between them:
From left to right, this table shows the CSAA, per the mixed model, for each catcher, above or below the league average; the run effect of that increased or decreased probability assuming 7,000 pitches in a season, at the standard value of .14 runs per additional strike; the same calculation for that catcher under the existing RPM/WOWY system; and the difference between the two. What is the Effect of Moving to CSAA? In particular, the mixed model is kinder to our most framing-challenged catchers. Even with the benefit of PITCHf/x data, the previous WOWY system absolutely slaughtered the bottom-end framers, holding them responsible, in some cases, for almost five losses a year over a full-time gig. CSAA doesn’t think Carlos Santana was a good framer either, but controlling for his pitching, schedule, and umpires, it was satisfied to penalize him a mere 23 runs lost per 7000 opportunities, about half the rate RPM/WOWY would assess. Nonetheless, CSAA and RPM remain in general agreement about most players. The Pearson correlation between the PITCHf/x mixed model and RPM/WOWY is .77, which is quite good. The mixed model also smoothed out the more abrupt shifts in the RPM/WOWY model for individual players over seasons. Take, for example, the trend for Jason Kendall between the years 2008 through 2010 and look at the difference in the decline of his measured framing ability as rated by WOWY vs. the CSAA mixed model:
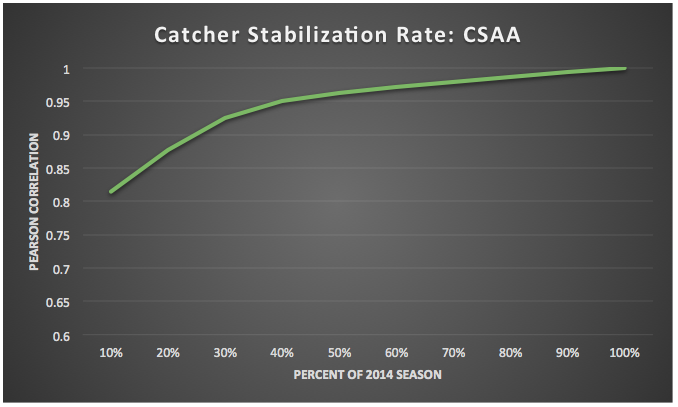
Whereas WOWY saw a series of very abrupt declines, the mixed model — still using only individual, within-season calculations — saw only a gradual decline. There are other examples like this, and while one possibility is that WOWY is correct and the mixed model is not, it seems more likely that the mixed model is benefiting from the fact that it compares everyone to each other, and recognizes that what otherwise might seem like an abrupt drop (or gain) in skill in the WOWY vacuum often can be explained in part by other league-wide factors. Last, but certainly not least, the stability of the CSAA skill, at least for catchers, merits special comment. We were particularly interested in seeing how quickly this skill stabilized over the course of a season. To find out, we took random stratified samples of the 2014 season in cumulative 10 percent intervals, modeled them separately, and compared them to the final “100%” numbers for each catcher. The correlations are astounding:
After only 10% of the season (about three weeks) a catcher’s 2014 CSAA sports a .81 correlation to his final number. After 30% of the season (about 2 months), the correlation is over .9. This isn’t just for full-time catchers either: this data set includes catchers like Humberto Quintero, who had a mere 35 framing opportunities last year.[3] CSAA is not only a skill, but one that manifests itself quickly and with effect.
What about pre-2008? This is the trickier part. As discussed in the Appendix, PitchInfo’s re-coded PITCHf/x data offers enormous benefit to the mixed model. Before 2008, there of course was no publicly-available PITCHf/x data. So, to go back further in time, we need to look for partial substitutes. We can do that, going back to 1988, by adding as fixed effects some of the attributes for which PitchInfo’s data accounts: the count in which the pitch was thrown, and the handedness of the pitcher and batter. The resulting estimates, although less precise, are reasonable. The correlation between the CSAA-Retro model and our PitchInfo CSAA model for the same seasons is .70 — which is more than acceptable and comparable to the correlation between CSAA and RPM-WOWY. According to this CSAA-Retro, which relies on Retrosheet ball-strike data, the top 20 pitch framing seasons before 2008 are as follows:
You will notice that all of these top seasonal values arise from 2001-onward. We think there is a good reason for that. Before 2000, the umpires used to work exclusively in one league or the other, reporting to the respective league — not MLB — office. In 2000 the umpires were consolidated into one universal staff. In 2001 we may have seen the first real impact of that change: more called strikes. The rate of called strikes per pitch taken (“CSR”) is generally on the rise over the period of interest, 1988 onward. CSR took a big leap in 2001 with the umpire consolidation, quite possibly ushering in a golden era of framing.
The second big jump on that chart began in 2009, and coincides with the adoption of PITCHf/x. This also does not seem like a coincidence, as MLB umpires switched from Questec to PITCHf/x for evaluation that same year. PITCHf/x also informed us a great deal on the value of framing, and here we are with framing all the rage. It’s also interesting to note that these higher run-value seasons come in an era where scoring is down: Average Run Value per Frame, 1988-2014
But what about those players from the pre-umpire consolidation? There were some great framers back then, too. Their impact was dampened by the environment, but CSAA-Retro still sees many of their framing contributions as substantial: Top 20 Framing Seasons, 1988-1999
The Models, Compared Let’s start with this plot, which shows all catcher seasons from the PITCHf/x era with at least 500 framing chances:
The raw PITCHf/x strike likelihood (“Raw CS_prob” from PitchInfo) is shown in red, and our existing PITCHf/x-WOWY system (“RPM-WOWY”) is shown in yellow. As you can see, WOWY helps a bit, but fundamentally this graph of red and yellow is mostly orange. In other words, the second step of WOWY wasn’t telling us a whole lot more than what we already were getting with PITCHf/x. What happens when we take the existing RPM-WOWY system and compare it to the CSAA mixed model options? We’re glad you asked:
The yellow line still represents the existing PITCHf/x-WOWY system, but now we have filled in those same 2008-2014 catcher seasons, as measured by CSAA, in purple. Benefitting from the within- and between-subject regression, the purple line still recognizes significant gaps in performance, but also finds many of the catchers to be less different than WOWY made them seem. WOWY, although generally reasonable, was allowing massive over-fits, which explains some of extreme values we were seeing. The mixed model sucks much of this noise out of the measurements and provides a more accurate estimate of framing ability. That noise, we suspect, comes from a variety of sources: the challenge to satisfactorily account for the effect of batters and umpires, the inability to consider the home-field strike-calling advantage, and, we suspect, some residual game-calling skill that was being credited to catchers by default as framing skill. Now that some of these factors are being specifically accounted for, we can have more confidence in our measurements of actual catcher framing. The last comparison is between CSAA and CSAA-Retro:
This chart shows why, even without PITCHf/x, we can go back to 1988 and still reasonably model catcher framing. As long as we have pitch counts, we can pull enough noise out of the system to catch the general signal. As one would expect, full CSAA with PITCHf/x is tighter and less noisy, but CSAA-Retro can certainly fit the bill when it is all that we have available. Bringing it All Together Top Framing Careers (1988-2014)
Brad Ausmus, looking good! Also a talented pitch receiver. Amateur dermatologists should take note of the nearly 14 wins of career value added by one Michael Joseph Piazza, an impressive and often-overlooked addition from an “offense-first” catcher. But it’s the name in fourth place that’s most interesting to us: Brian McCann. You may recall from our earlier research that Mr. McCann was beloved like no other. Although he still ranks highly, CSAA is somewhat more skeptical, apparently believing that McCann was benefitting substantially from some combination of at least two factors. First, PITCHf/x provides precise location and pitch type data, so McCann’s framing talents manifest differently when we are able to include that information. Second, the WOWY procedures may have not successfully accounted for the makeup of his pitching staff and fellow catchers. The two systems did wind up closer in the past two seasons, and they followed the same overall ups-and-downs in the earlier years.
The Minor Leagues While the data does extend to Single-A and Single-A Advanced in the past two seasons, we are only comfortable at this point in using Double-A and Triple-A numbers. We have Triple-A data as far back as 2006, and Double-A starting in 2008. Using the same techniques and model as the Retrosheet data, we now have minor league framing. Super-prospect Austin Hedges has the best minor league framing season on record to date. Tony Wolters, who moved from infield to catcher, trails Hedges from a distance. Top Five Triple-A Framers, 2014
Top Five Double-A Framers, 2014
Aging
We used the delta-method endorsed by Mitchel Lichtman and considered MLB catchers dating back to 1988. Between season “deltas” were restricted to be within system (Retro-CSAA to Retro-CSAA, CSAA to CSAA). Under CSAA, framing ability peaks around age 25, declines gradually until about 32, and then starts falling off a cliff, although certain catchers (the Jose Molinas of the world) hold on to the ability longer than most. As we continue to study the minor league data, we hope to refine this curve. This, along with Minor League Equivalents (MLE), will allow us to incorporate CSAA into PECOTA. Summing It Up To allow everyone to participate, please post any initial thoughts in the comments below, which we will monitor and make every effort to address. We’re also happy to consider other formulations (or explain why they are not feasible) and answer technical questions. Down below, we’re providing some resources to educate those interested on how mixed models work, both generally and in R. Within a few weeks thereafter, we expect to make any necessary adjustments and advise of you of what they are. We will also provide instructions on parsing the Retrosheet data so you can reproduce that element of the study in its entirety. Finally, we plan to integrate the new metric with FRAA, WARP and PECOTA. Baseball analyst Chris Long has also shown the way to NCAA baseball data, so we hope to add college framing metrics before long, too. We’ll even look for NPB and KBO data, because why not? And we’re certain explorations of the batter and pitcher CSAA data will appear before long. We look forward to working with you, and hope you find this project as interesting as we have. We’re working on a topic that has been discussed for roughly a century, so don’t feel like you’re late to the party. General References and ResourcesBates, Douglas. (2010). lme4: Mixed-effects modeling with R. [http://lme4.r-forge.r-project.org/lMMwR/lrgprt.pdf] Bates D, Maechler M, Bolker B and Walker S (2014). lme4: Linear mixed-effects models using Eigen and S4. R package version 1.1-7, [http://CRAN.R-project.org/package=lme4] Knowles, Jared. (2013). Getting Started with Multilevel Modeling in R. [http://jaredknowles.com/journal/2013/11/25/getting-started-with-mixed-effect-models-in-r] Luo, Xianghua. (Fall 2014). PubH 8452 Advanced Longitudinal Data Analysis. [http://www.biostat.umn.edu/~xianghua/8452/index.htm] Marchi, Max. (2013). Catcher Framing Before PITCHf/x. [http://www.baseballprospectus.com/article.php?articleid=20596&mode=print&nocache=1416171684] Marchi, Max. (2011). Evaluating catchers: Quantifying the framing pitches skill. [http://www.hardballtimes.com/evaluating-catchers-quantifying-the-framing-pitches-skill/] Tango, Tom. (2008). With or Without You. Hardball Times Annual 2008, pp. 100–146. Tango, Tom. (2008). With or Without . . . Derek Jeter. Hardball Times Annual 2008, pp. 147–152. Winter, B. (2013). Linear models and linear mixed effects models in R with linguistic applications. arXiv:1308.5499. [http://arxiv.org/pdf/1308.5499.pdf] Thanks to Russell Carleton and Brian Mills for their input. Research assistance provided by Rob Willer. AppendixFor those who like their math not only gory, but explicit, here are some further details on the models: The PITCHf/x CSAA Model Specification CSAA, which is the PITCHf/x (PitchInfo) version of the model, looks like this: glmer(cs ∽ cs_prob + half + (1|catcher) + (1|pitcher) + (1|umpire) + (1|batter) + (1|catcher:cs_prob), y, family=binomial(link = “probit”), nAGQ = 0) Here’s the guided tour, in order of appearance:
Here is the summary output for 2014 under the PITCHf/x version of the model:
Our desired output is the individual “random” effect of each catcher, but it takes a bit of work to get there. Doing so starts with the fact that random effects are “error” which, in our original equation, were additive: something added on to the fixed effects, but which cancel themselves out if all summed together. Here, the model is giving us two outputs of particular interest. First, it provides the fixed effects: an intercept (-1.93) and coefficients (half, cs_prob) which combine to generate the league average strike probability with a league-average collection of participants for an average pitch. Second, it provides a “random effect” intercept for each participant, which is the predicted effect of that participant, above or below 0, on whether a pitch in which they participate will be a strike. (For those who are curious, these values are conditional modes, estimated by maximum likelihood). Those individual intercepts are not contained in the summary page, above; they need to be separately queried with the ranef function. But the summary does show the categorical variance for each type of random effect, which tells you the relative effect of each category on the output; as you can see, on average catchers have about twice the effect (.027) of a pitcher (.014) on whether a borderline call ends up being called a strike, and almost three times the effect of the batter or umpire (.011). To determine the individual effect of each participant in our model, we need to compare the likelihood of a called strike when that individual is involved versus the “null” situation: the likelihood of a called strike with the middle-of-the-road collection of participants. To get this null baseline, we (a) add the fixed intercept to the median values of the continuous variable(s), and (b) convert this sum to an average probability (using R’s pnorm function). To evaluate individual participants, we add the value of the null baseline to their unique random effect and convert that sum to its own probability. Finally, we subtract the league-average (null) probability from each individual participant’s summed probability to get a final, net called strike probability attributable to that participant’s involvement in each pitch. Simple, right? The CSAA-Retro Model The loss of PITCHf/x from the pre-2008 seasons is notable. To give you a sense of its impact, the Akaike Information Criterion (AIC) for the model including PitchInfo’s cs_prob fixed effect was 151,206; without cs_prob, the AIC jumps up to 405,920. (Lower is better). Nonetheless, by including the pitch count and handedness of pitcher and batter, we can make up some of the lost ground. Accounting for interactions, that gives us this equation for CSAA-Retro: glmer (cs ~ throws*stands + home_batting + count + (1| catcher) + (1|pitcher) + (1|umpire) + (1|batter), y, family=binomial(link = “probit”), nAGQ = 0) This is better than the previous model with cs_prob taken out, but still leaves something to be desired, seeing as the AIC value is reduced only to 330398. Nonetheless, as discussed above, the results for CSAA-Retro are reasonable and correlate well with the PITCHf/x values, for seasons where both metrics are available. How Was the Overall Model Format Selected? Excellent question, and one that should stir some interesting discussion. Typical, best-practice model selection would involve the creation of separate training and testing sets from the data; trying out multiple modeling options on the training set, preferably with bootstrap resampling; and then fitting the various models to the test set to select the underlying model. However, that procedure is not entirely applicable here. First, we’re only taking the data one season at a time, and are not trying to predict future results. Rather, we’re characterizing the relationships within a season, each one of which is treated essentially as its own population. Second, unlike most modeling situations, there aren’t many choices of mixed models. Generally speaking, if the model is mixed, the model is either linear or it is not. The available variants are either fairly new or designed to accomplish objectives (e.g., variable selection) that are not particularly helpful here. As our relationships (thankfully) seem to be linear, there really is only one generally-accepted option to use. Third, the process of splitting and comparing subsets of mixed model data is a bit tricky. After all, we are talking about interactions that are both crossed and imbalanced; taking random samples out of that data, even if attempts are made to stratify it, can result in some imbalances when we try to predict out of sample. For our purposes, we selected the generalized linear mixed model. To find the best fit, which involved adding and subtracting various predictors, we used ANOVA to compare the various fixed-effect options, and the Akaike Information Criterion (AIC) to select the final model parameters, which were applied to each season.[4] The AIC is a well-known method of selecting among comparable model options. For those unfamiliar with it, individual AIC values have no value in and of themselves; their value is that as the model improves, the AIC score goes down. In particular, AIC helps grade whether the complexity of the model is providing an adequate return on the investment. As we noted before, the lower the AIC value, generally speaking the better the model. And a model that can provide better results with less complexity is generally preferred. The ideal measure to evaluate mixed effects models remains under active discussion in the statistical community: measures like marginal AIC (mAIC) and conditional AIC (cAIC) have been proposed, although both have limitations and are computationally intensive. Some have argued that traditional measures like AIC should not be used at all. However, our view is that, particularly when combined with the analyses above, AIC is a reasonable indicator of our mixed model’s good quality. Lastly, some of you may be curious about the choice of the probit link, which is not a typical choice. We started, as most people do when modeling binomial functions, by using the logit link. In the process of some Christmas Eve due diligence, however, we tried out alternative links, including probit, cauchit, and cloglog. We found that probit actually generated the lowest AIC values. It has also been argued that probit is more mathematically suited to predicting random effects because those effects are assumed to be normally distributed and have latent attributes that are better captured with that distribution. As such, it made sense to use it here.
[1] From this season forward, Retrosheet data provides a near complete set of pitch-by-pitch “sequences” for each plate appearance. The Retrosheet information used here was obtained free of charge from and is copyrighted by Retrosheet. Interested parties may contact Retrosheet at “www.retrosheet.org”. [2] Passed Ball / Wild Pitch (PBWP) modeling will be addressed in a separate article. [3] The data set excludes only the three 2014 catchers with less than 10 framing opportunities, as they did not appear often enough to be stratified across each sample. [4] The alternative measures of model fit generated by the lmer package — BIC, log likelihood, and deviance — all moved in lockstep with the AIC here.
Jonathan Judge is an author of Baseball Prospectus. Follow @bachlaw
|
I'll have to read that about 10X but on the the top framing careers, is there a metric which shows top framing runs "amount of opportunity" (innings caught) for instance, if yadier molina has had more opportunities than Brian McCann or Lucroy on a ratio basis, would they be better?
Using raw CSAA (per frame chance) our top five are
J. Molina .028
J. Lucroy .022
C. Vazquez .021
C. Stewart .021
R. Rivera .020
Yadi checks in at .013, McCann .011. Scioscia, btw, checks in at a robust .017 in the pre-golden era of framing _and_ at the tail end of his career. Very impressive.
BTW, for a quick rule of thumb, each .01 of CSAA per chance roughly translates to a single Win Above Average over the course of a full season.
Thank you, where does back acne check in?